CE$^4$L: Continual Ego, Exo, and Ego-Exo Learning
Abstract
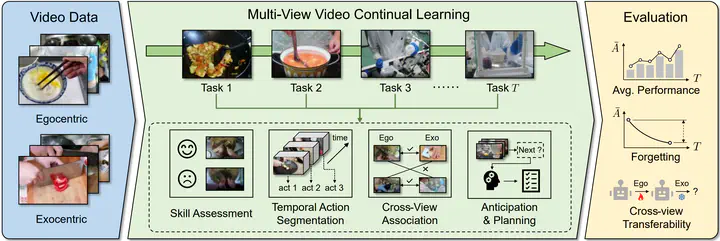
Perception for embodied agents is video-based, often multi-view (ego, exo, or both), and inherently continual, with simultaneous task and viewpoint shifts. Yet continual learning (CL) remains dominated by exo-only recognition tasks, obscuring behavior under these real-world coupled shifts. We introduce Continual Ego, Exo, and Ego-Exo Learning (CE4L), a unified multi-view CL benchmark spanning four representative tasks: cross-view referenced skill assessment, temporal action segmentation, cross-view association, and action anticipation & planning. CE4L highlights challenges largely absent in prior CL benchmarks, including cross-view correspondence, view-dependent asynchrony, and heterogeneous semantic objectives. To this end, we propose Video Incremental Subspace-routed Task Adapters (VISTA), a parameter-efficient baseline method that stores task-specific updates in lightweight adapters and performs training-free routing via residual distance to task-specific whitened subspaces estimated from second-order statistics. Extensive experiments demonstrate the significantly varied efficacy of representative CL methods across CE4L settings, while VISTA is consistently competitive and achieves state-of-the-art overall performance.